文件结构分析
前文 中通过简单地观察 .HD 和 .BIN 的对应关系以及大量的 \xFF 分隔符,实现了文件的初步提取,但是 NORMAL、SCENE_ID、SCENEDAT、SYSTEM、VOICE_ID 六个 .BIN 中,我们仅成功恢复了明文保存的 SYSTEM 以及 ADPCM 的 VOICE_ID,其余 4 个文件格式仍然未知。
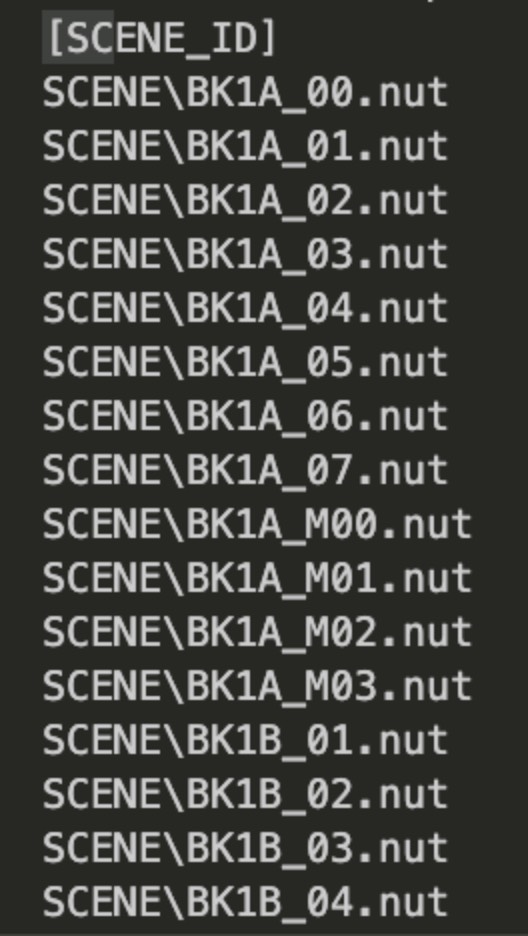
我们首先从文件较小的 NORMAL 开始分析。多分析几个文件可以发现比较明显的特征:首先文件开头 4 个字节是一个 int 数字,根据分析 .HD 中的经验,推测可能是文件大小,但是这个数字总是比我们提取出的文件的文件大小要大。接着 4 个字节取值为 1、2、3、4、5、6、7、8、9、10,推测是一个标识位,之后一个字节是非 ASCII 字节。从第 10 个字节开始是文件的正文。
在第 9 个文件中发现了大量明文,看起来是一个结构类似 ini 的配置文件,而且根据内容判断是 SYSTEM 中每个 nut 文件的名字,但是其中仍然包含了不属于明文的字节。
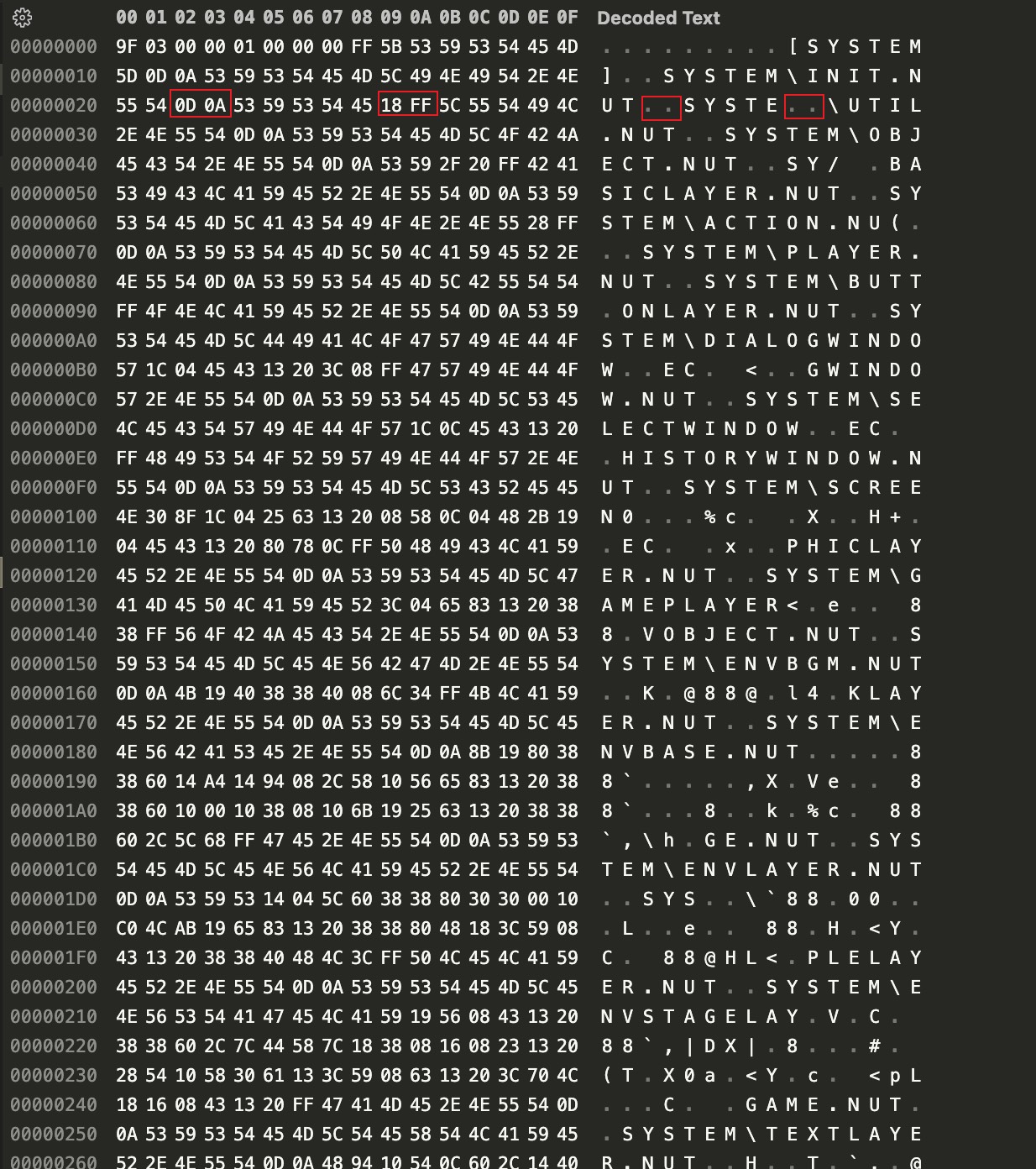
同样在 NORMAL 的第 13 个文件中也发现了应该保存 NORMAL 中的文件名的文件,那么首先可以确定这两个文件一定是以明文保存的文件。
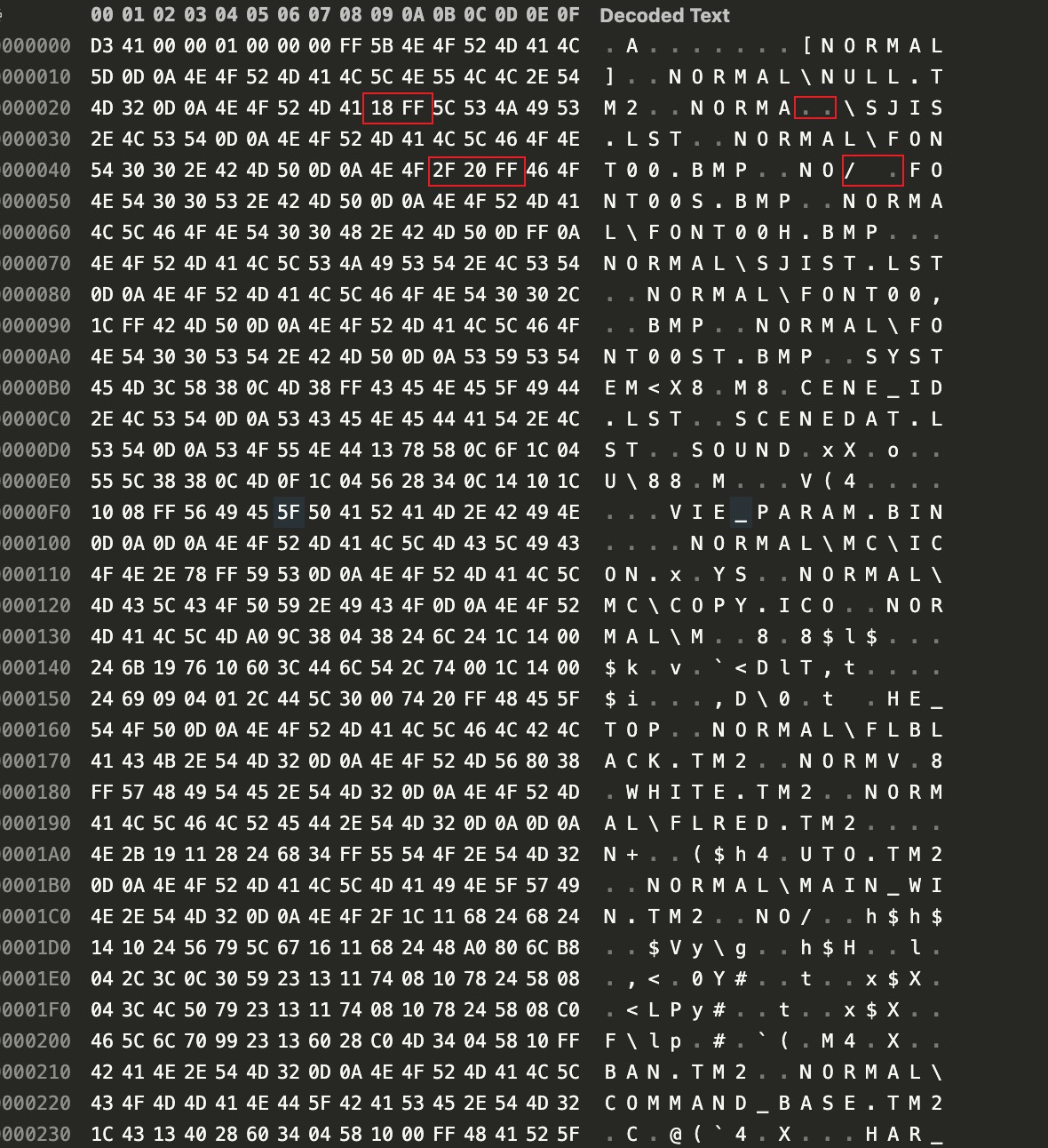
分析文件内容可以发现,大部分非 ASCII 字节连续序列以 \xFF 结尾,并且结合字节序列前后文本可以推测该文件被某种加密算法压缩,以及文件开头 4 个字节的 int 是文件压缩前大小。
将各种已知压缩算法均尝试了一遍以后,发现这是游戏作者自己实现的压缩技术。懒得逆程序,Google 了一下,发现有人也在逆向这个游戏,但是同样被这个 16 年前的压缩技术所困惑。帖子 里有两个老哥通过逆向游戏主程序,找到了解压缩函数,并且提取出了算法。
首先第一个老哥 Raccoon Sam 给出了自己的理解:
Hey there!
Bad news – I really can’t wrap my head around it, I’m afraid :CI’ve got samples for a compressed TIM2 file (“paktim” is just my nomenclature) extracted from the SCENEDAT and a legitimate, uncompressed counterpart TIM2 for it extracted from your save state. You can download them > here.
The first eight bytes in the paktim are a header; 40 64 04 00 01 00 00 00 which should be read as two words, 00046440 00000001 which in turn just define the uncompressed size (0x46440 or 287808 bytes, which unsurprisingly is the file size of the legitimate TIM2 file) and the amount of files in the entry (1, which > unsurprisingly is the … uh, amount of files)
After that, you read a byte as the variable instruction.
Logical AND instruction with 0x1F and add 2 to it to get the variable amount.
Shift instruction right five times to get the variable method.According to the method and amount, read bytes from the bytestream:
Method 7 is just “read amount bytes and write them to output”.
Method 6 is “read 1 byte as surrogate and then repeat that byte exactly amount times to the output”.
Method 0 is “repeat FF exactly amount times to the output”.The other methods are…. yeah, I dunno. Some methods look like they make sense but then the same method used later in the file does something completely different. I really can’t figure out what the trick here > is. Really hope someone else takes a look at this, it’s driving me nuts!!
文件开头 4 个字节的确是未压缩大小,之后 4 个字节帖子里的老哥认为是文件数量(不过这个并不是文件数量),之后读取 1 个字节作为 instruction,并进行 2 个运算得到 2 个变量:
instruction & 0x1f + 2可以得到amount变量。instruction >> 5可以得到method变量。
如果 method 是 7,则读取接下来 amount 个字节作为输出。
如果 method 是 6,则读取下一个字节并且重复 amount 次作为输出。
如果 method 是 0,则重复 \xff 字节 amount 次作为输出。
不过这哥们道行还是有点浅,并没有逆完整,所以这个并不是最终的解压算法,就在这哥们放弃以后,有一个老哥 rufaswan 觉得很有意思,并且接着逆出了“看似“完整的解压算法:
I can see why this game trip you up. I don’t think I saw this kind of compression algorithm before. But I have a good understanding of it now.
Let’s use an example for a start, you want to duplicate 0xC9 for 0x40 times. First you use method 6 for 0x1f+2 bytes, so you’ll get “DF C9”. For the remaining 0x1f bytes, you repeat the last command, or method 0, but with length 0x1d+2 instead, so you’ll get “1D”.
Hence, the compressed data to duplicate 0xC9 for 0x40 times is “DF C9 1D”.
And the game keep the last 6 commands as history, or method 0 to 5.
首先文件开始的 8 个字节就像上一个老哥逆的一样,是文件大小和文件数量(实际并不是文件数量),之后读取一个字节 BYTE,计算出 2 个变量:
BYTE & 0x1f可以得到LEN变量BYTE >> 5可以得到METHOD变量
如果 METHOD 是 7,则读取接下来 LEN + 1 个字节作为输出。
如果 METHOD 是 6,则读取下一个字节并且重复 LEN + 2 次作为输出。
在上述操作完成后,将其作为 current 放入 HISTORY 队列末尾:
1 | HISTORY[5] = HISTORY[4] |
如果 METHOD 在 [0,5] 之间,则作为 current 并且重新整理在HISTORY 中 METHOD 之前的所有元素,例如当 METHOD 是 3 时,则:
1 | HISTORY[5] // do nothing |
如果连续的 METHOD 是 6,则重复下一个字节 LEN + 2 次作为输出。
如果连续的 METHOD 是 7,则从 LEN 中提取 2 个变量:
LEN & 3得到变量SUB_LENLEN >> 2得到变量SUB_POS
之后从 SUB_POS 开始读取 SUB_LEN + 1 个字节作为输出。
最后这个老哥给了他对应的 PHP 代码
1 | function update_dict( &$dict, $lv, &$e ) |
这个老哥解释的比较抽象,实际上这是一个分块压缩算法,用一句话总结:解压缩时,对于每个 chunk 的第一个字节,低 5 位保存了长度,高 3 位保存了压缩方法,之后利用一个队列实现流式的 chunk 解压缩。
用这个老哥提供的代码写了个对应的 Python 版本进行解压缩,前文中提到 NORMAL 中第 9 个和第 13 个文件都成功解压缩,并且解压出了部分 TIM2 图片和 BMP 图片,其中 BMP 图片很明显是一个码表。

不过很可惜,这老哥逆的也不完整,按照这老哥的解压算法,仍然有部分文件解出来仍然是一个未知格式的文件,但是根据前面提到的 第 13 个文件包含了 NORMAL 中的文件名,在第 10~12 这三个文件中理论上应该保存的也是明文,但是解压出来的却是乱码。
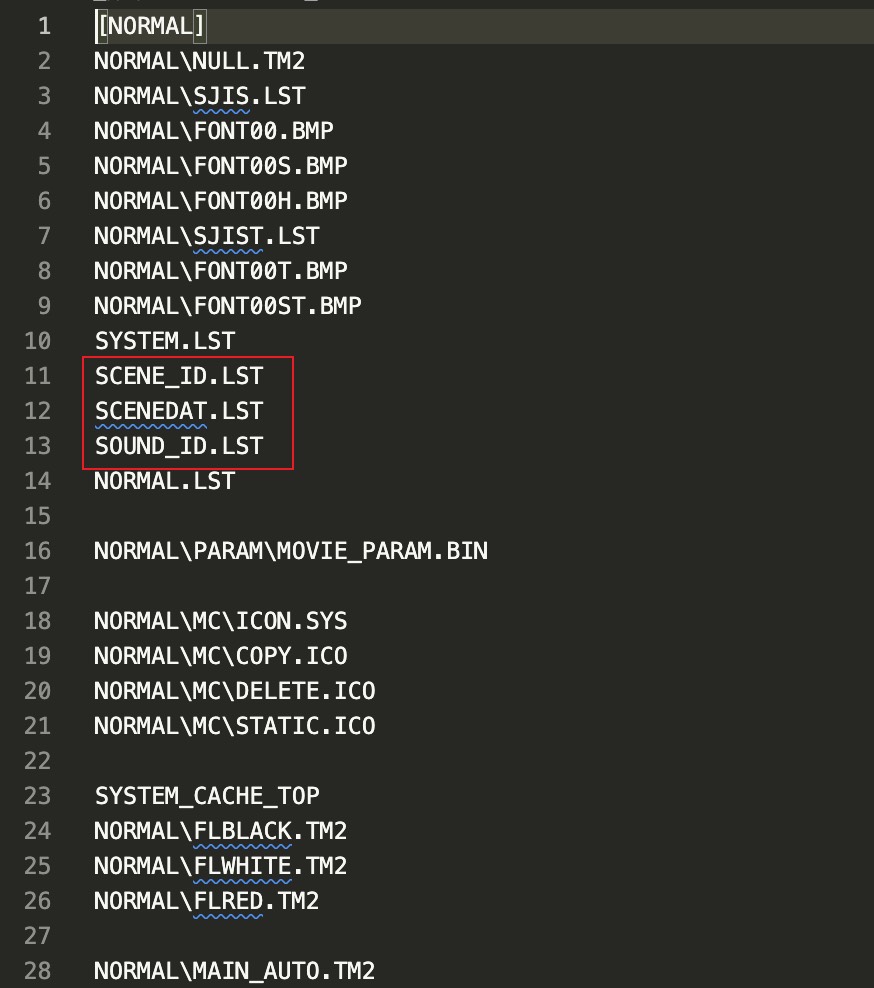
例如第 10 个文件 SCENE_ID.LST 解压出的效果如下,很明显不可能是文件名列表。
通过 review 老哥的算法可以发现,从始至终都没有使用过文件开头的第 5~8 个字节,也就是前文中所谓的”文件数量“,这 4 个字节如果没有任何作用的话也就不会被塞在文件开头并且占用 4 个字节的空间,对于寸土寸金的 PS2,4 个字节也是挺奢侈的。
实际上通过观察解压缩失败与成功的文件,可以很容易得出结论:当第 5~8 个字节是 1 时,才会解压缩成功,否则解压缩出的就是乱码。至此我们推测,这个数字要么是表示压缩算法的种类,要么作为一个常量参与解压缩运算中,只不过当其取值为 1 时,这老哥的解压缩算法刚好正确。总之这老哥逆向逆一半,最后还得自己亲自逆,好在这老哥在代码中提供了解压缩函数的地址 sub_116048,自己动手,丰衣足食。
MIPS 逆向准备
前文 中脚本语言分析完成后,还有存在很多没有定义的函数,那么剩下来的只有游戏主程序 SLPS_258.97 中可能存在这些函数的定义以及实现。好在 Ghidra 提供了 MIPS 反编译能力。虽然 PS2 的 CPU 5900l Emotion Engine 使用了 32 位的 MIPS-III,但是却是自定义的精简 MIPS 指令集,类似 microMIPS,在 MIPS16e 的基础上增删了一些指令。
Srpopty: Does the PlayStation2 use MIPS16e?
Bard: No, the PlayStation 2 does not use MIPS16e. It uses a custom RISC processor called the Emotion Engine (EE). The EE is based on the MIPS III architecture, but it includes a number of extensions that are not found in MIPS16e. For example, the EE has a floating-point unit, which is not present in MIPS16e. The EE also has a number of instructions that are specifically designed for multimedia applications.
The PlayStation 2 was released in 2000, and at the time, MIPS16e was not a widely used architecture. MIPS16e was designed for embedded systems, and it was not considered to be powerful enough for high-end gaming consoles. The EE was a more powerful architecture that was better suited for the PlayStation 2’s target market.
Here are some additional details about the Emotion Engine:
The Emotion Engine is a 32-bit RISC processor.
The EE has a clock speed of 300 MHz.
The EE has a 2 MB L2 cache.
The EE has a floating-point unit.
The EE has a number of instructions that are specifically designed for multimedia applications.
The Emotion Engine was a powerful processor for its time, and it helped to make the PlayStation 2 one of the most successful gaming consoles of all time.
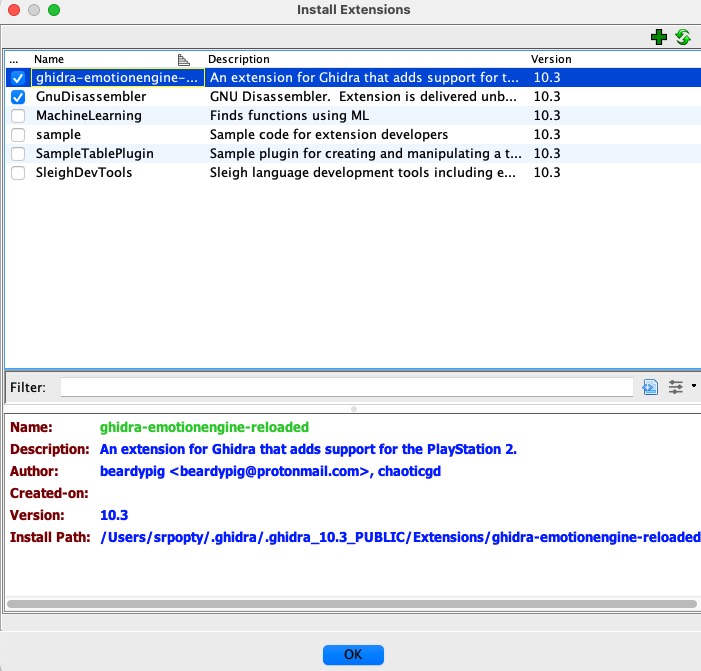
因此直接用 Ghidra 内置的 MIPS 处理器无法完全识别所有指令,因此需要安装额外的 Ghidra 扩展 ghidra-emotionengine 或者 ghidra-emotionengine-reloaded,根据 Ghidra 的版本安装不同的 Release,其中 ghidra-emotionengine 仅支持到 9.3,之后的 Ghidra 版本需要使用 ghidra-emotionengine-reloaded 提供的 Relase。
下载好的 Ghidra 扩展是一个 zip 压缩包,将解压后的文件夹移动到 ~/.ghidra/.ghidra_xx.xx_PUBLIC/Extensions/ 目录下,之后在 GUI 的 Project 界面的 File 下就可以加载扩展
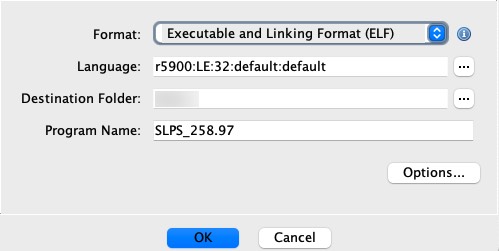
之后重启 Ghidra 后就可以用扩展提供的 r5900 处理器分析 SLPS_258.97,这时就可以正常解析指令。
解压缩算法逆向
逆向工作准备完成后,马不停蹄地来到前面老哥提供的解压缩函数 0x116048 处,结合 PCSX2 的 debuger 做了一些简单的分析(PCSX2 的 debugger 是真难用):
1 | void decompress(byte *data,byte *dst,int param_3,ulong size) |
果然老哥没逆错,这个函数的内容和老哥逆出来的一样,从 data 中解压数据到 dst 中,queue 就是老哥的 HISTORY,表达式 (xxx & 0xe0) == 0xc0 等价于 xxx == 6,(xxx & 0xe0) == 0xe0 等价于 xxx == 7。
发现这个函数中也没有使用前面提到的文件中第 5~8 个字节(为了表达方便,我们记为 unknown),只用了前 4 个字节 size,那么就回到这个函数的调用者,看看调用者在执行完这个函数后会不会对 dst 做其他处理。
1 | ulong decompress_chunk(byte *chunk,byte *result,long param_3,long param_4,long param_5, |
其中 chunk 就是一个文件的内容,dst 是 decompress 解压的输出,可以看到第 33 行执行完 decompress 后,取出 chunk 的第 5~8 个字节小端转换为 int 作为 unknown,最终带着 dst、为压缩文件大小 decompress_size 和 unknown 调用了 FUN_00116348 函数,并且结果放在 result 中,作为 decompress_chunk 函数的返回结果。
那么很明显,FUN_00116348 就是那个老哥没有逆干净的代码,进去看看这个函数用 unknown 干了啥。
1 | void FUN_00116348(byte *buf,byte *result,int size,long unknown) |
果然,我们前面的推理没错,unknown 确实作为一个常量参与解压计算,FUN_00116348 会基于 unknown 对 decompress 的结果进行新一轮解压,当 unknown 取值为 1 时,这个函数原封不动的复制 buf 到 result 中,这就是为什么老哥逆出来的解压算法只能成功解压 unknown 为 1 的文件。
最终,基于 FUN_00116348 的逆向结果,重新解压 NORMAL 的第 10 个文件 SCENE_ID.LST,这次解压出了正确的结果。
此外,通过逆向可以发现,前文中发现 .BIN 中每个文件之间总是间隔大量 \xff 只是为了将文件对其到 0x800,便于寻址。