前言
最近几个月迷上了某上古动漫,希望借助 AI 技术复活动漫中的女主角。经过一番搜罗发现该动漫居然出过三款 PS2 文字冒险游戏,为了方便收集训练数据,需要从这三个 PS2 游戏中提取一些资源。然而毕竟是上古动漫,而且从来没接触过 PS2 的逆向,本文记录了一个 Web 狗针对一个上古 PS2 游戏的逆向全过程。
作为一个上古时期的动漫,第一款 PS2 游戏发售的时候北京奥运会都还没举行,因此在这个年代找到这三款上古游戏的资源确实是不容易,不过最终经过三天的努力,借助 Google Hacking 以及其他 Web 手段下载了这三款 盗版 游戏。
PS2(Sony PlayStation2)是一款非常古老的游戏主机,在现代 Mac 系统上使用 PCSX2 模拟器 运行 PS2 游戏的效果还不错,不过需要下载 BIOS,当然,借助 Google Hacking 还是比较容易找到这些 PS2 的 BIOS,包括欧版,日版,美版等。
逆向之前先试着玩了玩,确定三个游戏都可以正常运行,可惜都是日文,年代太久远了没有任何汉化,文字冒险游戏只看日文也确实玩不明白,只能听个响看个图,外网搜索了很久也几乎没人关注这个游戏的逆向,因此一切都需要从头开始。本文工作量较大,内容较多,将分为多个部分记录。
目录结构与文件分析
下载好的游戏都是常见的游戏光盘 iso 格式,直接打开 iso 就可以看到里面的目录。由于三个游戏都是同一家厂商开发,因此本文主要以其中一个游戏进行逆向。游戏本身 1.9G 左右,打开 iso 光盘里面的目录结构如下:
1 | /Users/srpopty/Desktop/xxxx |
大概了解一些 PS2 的开发基础,相较于现代游戏主机,PS2 的开发较为自由,换句话说就是不太规范,各种文件、脚本、字节码这些格式开发者甚至可以自己定义。
首先在 CD 根目录中,SLPS_xxx.xx 一般作为游戏主程序,也就是主要入口,游戏运行时首先执行的就是就是这个程序,从 SYSTEM.CNF 中也能看到这个信息,file 一下也可以看到是 32 位的 mips,静态链接,无符号表,可以用 IDA 反汇编,或者直接用 Ghidra 反编译。
1 | ELF 32-bit LSB executable, MIPS, MIPS-III version 1 (SYSV), statically linked, stripped |
此外还可以看到两个目录 IOP 和 MOVIE。在 PS2 中,IOP 类似 Windows 的 .dll 以及 Unix 的 .so,属于动态链接库,file 一下目录中的 .IRX 文件也可以看到是和 SLPS_xxx.xx 一样的 MIPS ELF,但是单靠文件名暂时不好判断其功能。而在 MOIVE 中的 .PSS 是一种视频文件格式,可以直接用 VLC 播放,但是没有声音,包括了厂商 logo、开头的 OP、结束的 ED 以及一个 WARP 视频。
之后在 CD 根目录下可以看到很多同名的 .BIN 和 .HD 文件,包括 NORMAL,SCENE_ID,SCENEDAT,SOUND_ID,VOICE_ID 以及 SYSTEM,用 file 或者 binwalk 也查不出来是什么类型的文件。
通过分析 .BIN 文件和 .HD 文件的大小(如下表所示),推测 .HD 与 .BIN 存在对应关系,.BIN 可能是多个文件打包,而 .HD 则存储了映射关系。
| Name | NORMAL | SCENE_ID | SCENEDAT | SOUND_ID | VOICE_ID | SYSTEM |
|---|---|---|---|---|---|---|
| .BIN | 12 MB | 7.4b MB | 171 MB | 363 MB | 1.2 GB | 906 KB |
| .HD | 2.6 KB | 2.3 KB | 8.4 KB | 724 B | 83 KB | 168 B |
首先根据文件名以及对应的文件大小可以大致猜出,SCENEDAT 中保存的可能是各种场景资源,例如贴图,SOUND_ID 中保存的是音效,而最大的 VOICE_ID 中保存的可能就是角色的语音。
本文的最终目标是提取出角色声音,也就是 VOICE_ID 中的音频以及对应的文本作为训练数据。
BIN 文件提取
既然 .HD 和 .BIN 是存在对应关系,那么首先要想办法利用 .HD 从 .BIN 中提取文件。首先以最小的 SYSTEM 为例,用 010 Editor 查看可以看到 SYSTEM.BIN 中保存了类似代码的明文数据

并且每隔一段距离就会出现大量的 0xff,类似分隔符
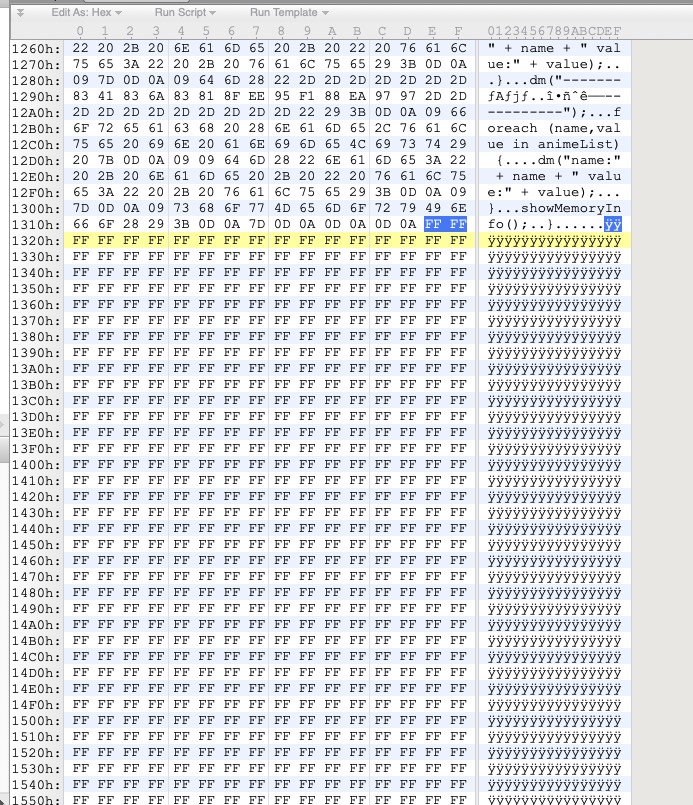
虽然可以看到类似代码的明文,但是其中也夹杂了很多不可见字符,此外明文中也可以看到很多 for、if 这种语法结构,因此不可能是某种语言的字节码,那么直接用文本模式打开 SYSTEM 可以看到不可见字符全部出现在了类似 C 风格的注释中。
考虑到这是个日本发行商的游戏,因此猜测可能是日文注释,重新用日文编码 Shift JIS 打开文件可以看到正常的文件内容,果然是用日语写注释。。。
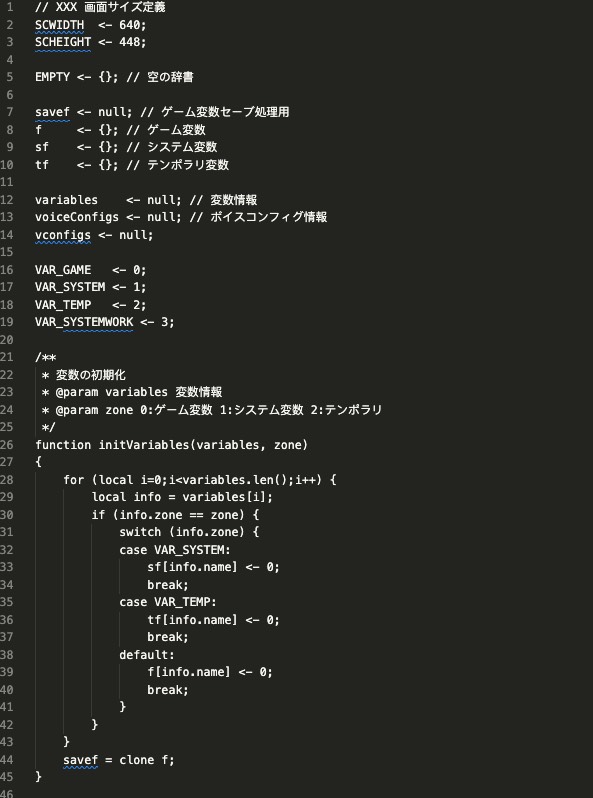
尽管目前可以看到某种类似脚本语言的明文代码,但是每隔一段代码都会出现大量的 0xff
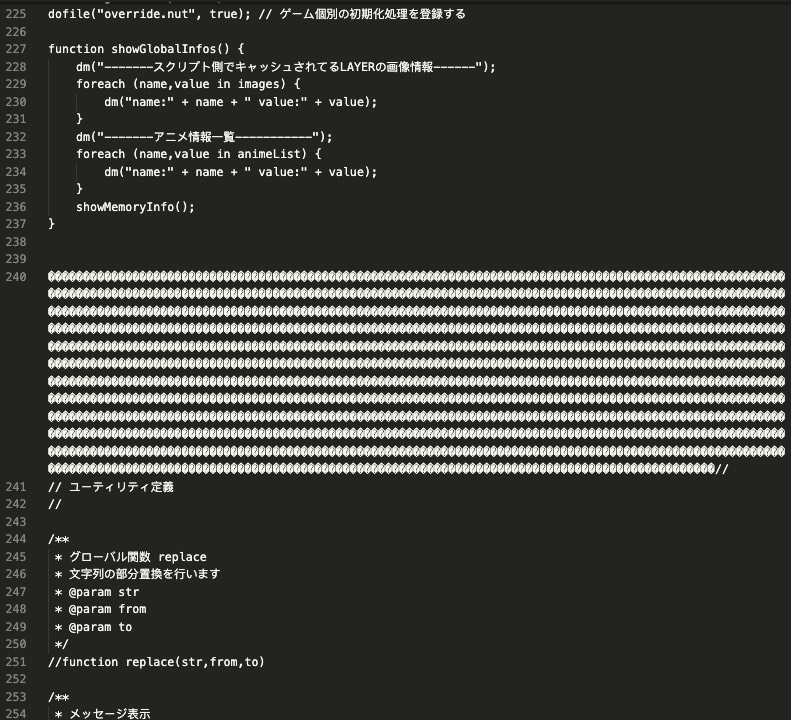
同时打开其他几个 .BIN 文件,也可以看到每隔一段就会出现大量的 0xff,并且出现的数量并不确定,但是总是会填充到整数后出现其他内容,推测 0xff 可能用于填充对其并分割不同文件,例如下图中 SYSTEM.BIN 的第一段代码被 0xff 填充并对齐到了 0x1800,作为一个 chunk
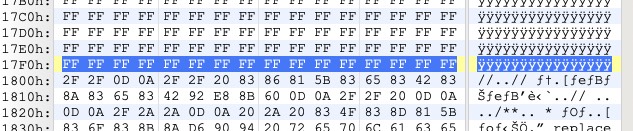
继续向后分析几段,可以发现每一个 chunk 的大小都是不同的,但都是整数,其实分析到这里基本可以确定大量的 0xff 的作用就是分隔文件内容,但是至于为什么要填充到某个具体的整数,原因未知,例如 SYSTEM.BIN 第一个 chunk 为什么填充到 0x1800 而不是 0x1700。
继续分析 SYSTEM.HD 中的内容
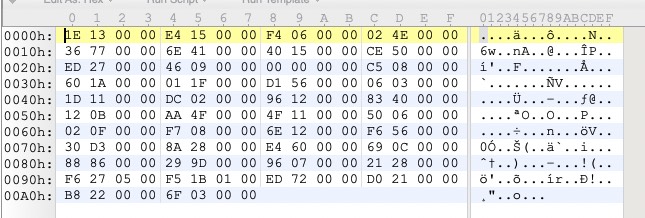
第一眼就可以看到大量的 00 00,少部分的 01 00,根据经验推测很有可能是小端存储的 int,每 4 个字节作为一个数字,查看其他几个 .HD 文件也可以看出 .HD 文件大小一定是 4 的倍数。但是每个 int 并没有什么规律,有大有小,也没有经过排序。
根据以往的逆向经历,例如对阴阳师 .npk 的逆向,通过头表(Header Table)中存储的偏移 offset 和文件长度 length 这两个值就可以从打包存储的数据中提取指定位置的文件,因此这个 int 一定是 offset 或者 length 之一,才会与 .BIN 相对应。假如 int 表示的是 offset,存储偏移的表通常是有顺序的,并且偏移一定是唯一的,而在某些 .HD 文件中出现了重复的值,因此这里的 int 一定不是偏移,怀疑可能是 length。
根据前文的结论,.BIN 的一个 chunk 前一部分保存了文件内容,后一部分保存 0xff 用于对齐分隔,假设 .HD 中第一个值 0x131e 对应的是 .BIN 中的第一个文件内容的长度而不是 chunk 的长度,验证一下
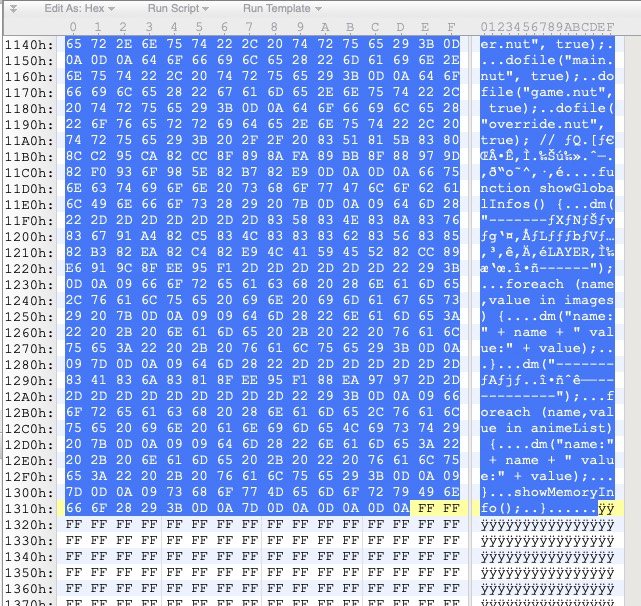
SYSTEM.BIN 中第一个文件内容长度刚好是 0x131e,对应 SYSTEM.HD 的第一个小端 int 1E 13 00 00,再验证一下下一个 chunk 刚好也是 0x15e4,对应 SYSTEM.HD 的第二个小端 int E4 15 00 00
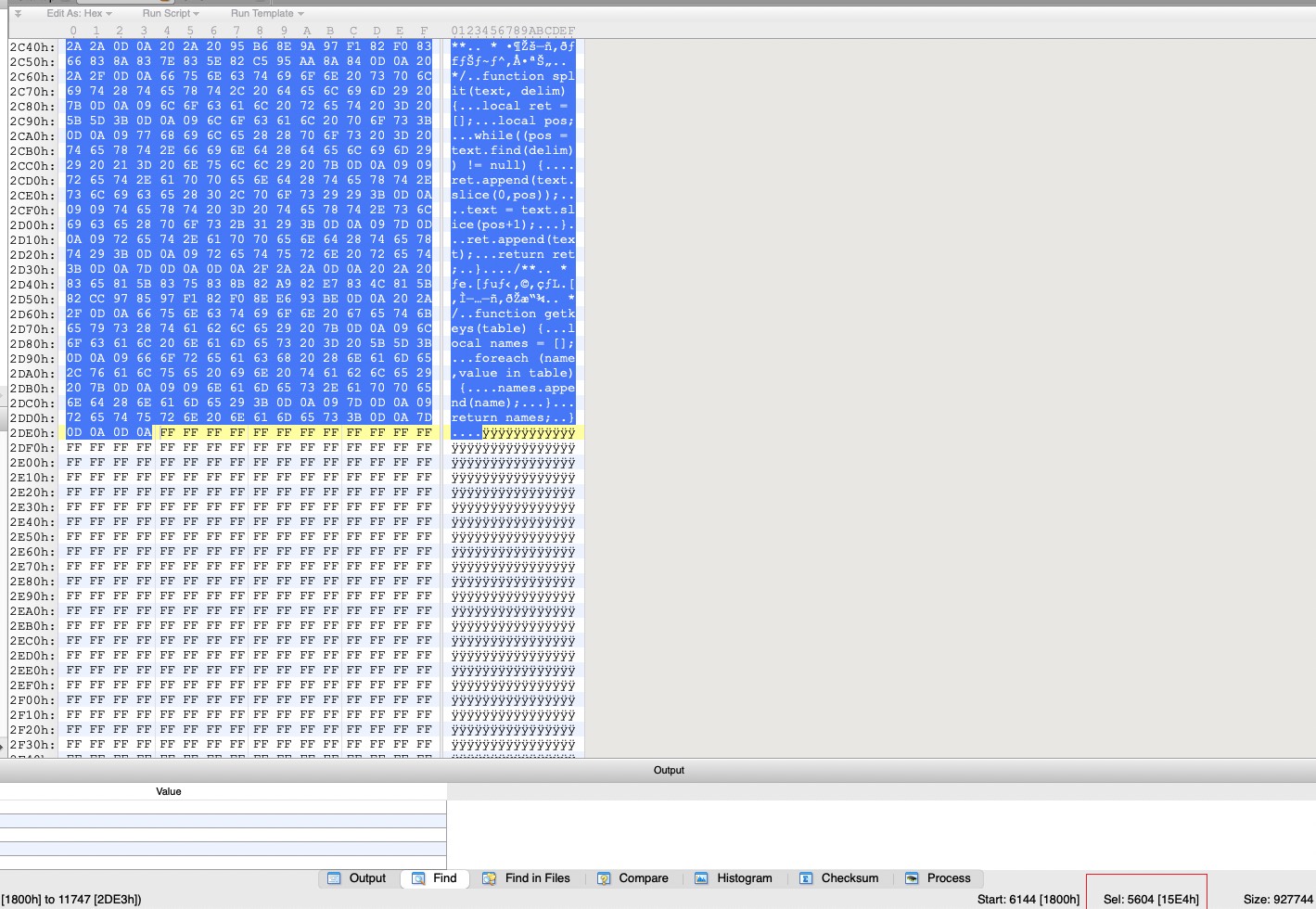
验证其他几个 .BIN 和 .HD 也可以得到同样的结论。到此,基本就可以确定 .HD 中保存的就是 .BIN 中每个文件内容的长度,并且每个文件内容后会被填充大量的 0xff 分隔同时对其到某个整数。那么基于此,可以写出对应的提取脚本
1 | #!/usr/bin/env python |
在 CD 根目录执行脚本 python extract.py <name> [ext=dat],例如
1 | python extract.py SYSTEM |
同时可以指定提取出的文件后缀,默认是 .dat
1 | python extract.py SYSTEM py |
提取出的文件后保存在 <name>_extracted 目录中,例如 SYSTEM_extracted,文件名为 id_offset_length.ext,其中 id 为文件序号,按照文件出现的顺序从 0 开始,offset 为文件在 .BIN 中的偏移,length 为 .HD中保存的文件内容大小。
最后按顺序提取出 NORMAL.BIN,SCENE_ID.BIN,SCENEDAT.BIN,SOUND_ID.BIN,SYSTEM.BIN 以及 VOICE_ID.BIN 中的所有文件。